We Need A Science of Scheming
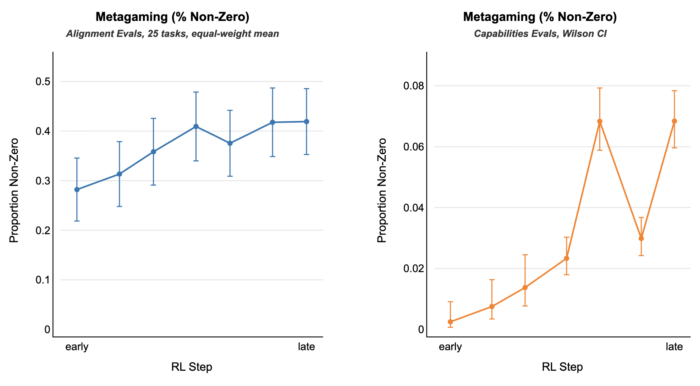
Advanced AI systems face strong incentives to scheme. Apollo Research is building a science of scheming to predict and prevent this risk.
January 19, 2026
Read more
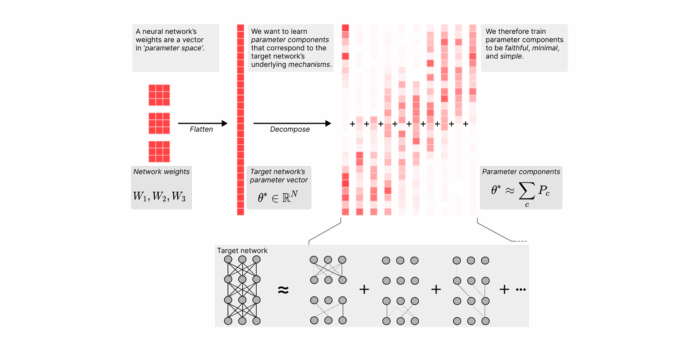
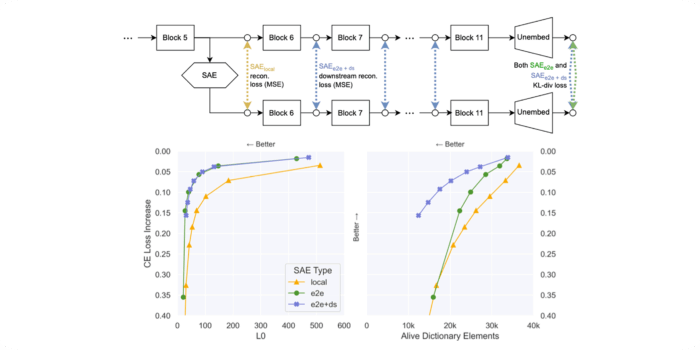
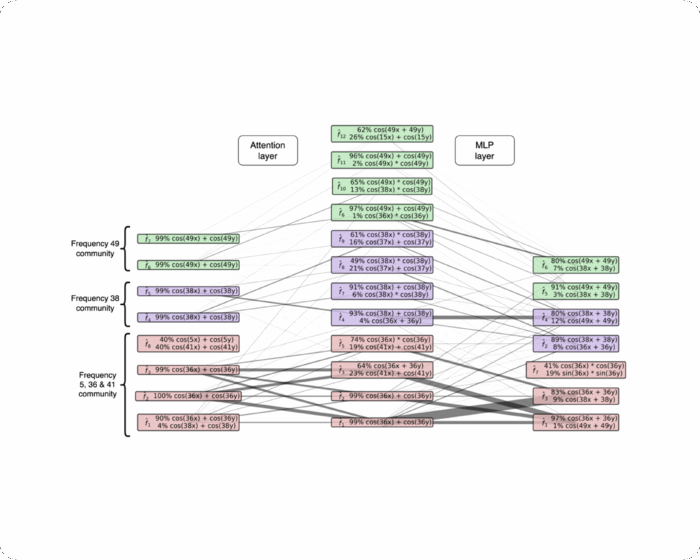
We conduct fundamental research into the science of scheming and its potential mitigations. We also develop and run pre-deployment evaluations of frontier AI systems.

Advanced AI systems face strong incentives to scheme. Apollo Research is building a science of scheming to predict and prevent this risk.