Identifying functionally important features with end-to-end sparse dictionary learning
A short summary of the paper is presented below. Read the full paper here. Accepted as Spotlight at the ICML Mech Interp workshop.
This work was produced in collaboration with Jordan Taylor (MATS + University of Queensland).
Introduction
Current SAEs focus on the wrong goal: They are trained to minimize mean squared reconstruction error (MSE) of activations (in addition to minimizing their sparsity penalty). The issue is that the importance of a feature as measured by its effect on MSE may not strongly correlate with how important the feature is for explaining the network’s performance.
This would not be a problem if the network’s activations used a small, finite set of ground truth features — the SAE would simply identify those features, and thus optimizing MSE would have led the SAE to learn the functionally important features. In practice, however, Bricken et al. (2023) observed the phenomenon of feature splitting, where increasing dictionary size while increasing sparsity allows SAEs to split a feature into multiple, more specific features, representing smaller and smaller portions of the dataset. In the limit of large dictionary size, it would be possible to represent each individual datapoint as its own dictionary element.
Since minimizing MSE does not explicitly prioritize learning features based on how important they are for explaining the network’s performance, an SAE may waste much of its fixed capacity on learning less important features. This is perhaps responsible for the observation that, when measuring the causal effects of some features on network performance, a significant amount is mediated by the reconstruction residual errors (i.e. everything not explained by the SAE) and not mediated by SAE features (Marks et al., 2024).
Given these issues, it is therefore natural to ask how we can identify the functionally important features used by the network. We say a feature is functional important if it is important for explaining the network’s behavior on the training distribution. If we prioritize learning functionally important features, we should be able to maintain strong performance with fewer features used by the SAE per datapoint as well as fewer overall features.
To optimize SAEs for these properties, we introduce a new training method. We still train SAEs using a sparsity penalty on the feature activations (to reduce the number of features used on each datapoint), but we no longer optimize activation reconstruction. Instead, we replace the original activations with the SAE output and optimize the KL divergence between the original output logits and the output logits when passing the SAE output through the rest of the network, thus training the SAE end-to-end (e2e).
One risk with this method is that it may be possible for the outputs of SAE_e2e to take a different computational pathway through subsequent layers of the network (compared with the original activations) while nevertheless producing a similar output distribution. For example, it might learn a new feature that exploits a particular transformation in a downstream layer that is unused by the regular network or that is used for other purposes. To reduce this likelihood, we also add terms to the loss for the reconstruction error between the original model and the model with the SAE at downstream layers in the network.
It’s reasonable to ask whether our approach runs afoul of Goodhart’s law (“When a measure becomes a target, it ceases to be a good measure”) We contend that mechanistic interpretability should prefer explanations of networks (and the components of those explanations, such as features) that explain more network performance over other explanations. Therefore, optimizing directly for quantitative proxies of performance explained (such as CE loss difference, KL divergence, and downstream reconstruction error) is preferred.
Key Results
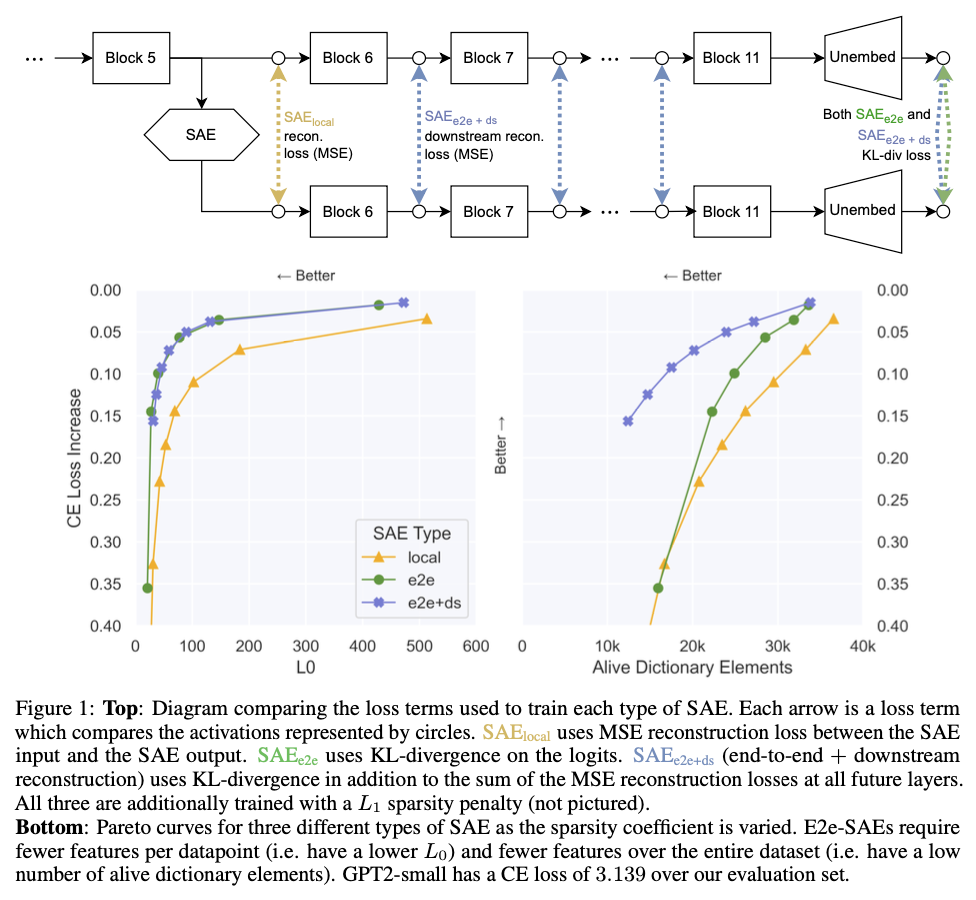
We train each SAE type on language models (GPT2-small and Tinystories-1M), and present three key findings (Figure 1):
- For the same level of performance explained, SAE_local requires activating more than twice as many features per datapoint compared to SAE_e2e+ds and SAE_e2e.
- SAE_e2e+ds performs equally well as SAE_e2e in terms of the number of features activated per datapoint, yet its activations take pathways through the network that are much more similar to SAE_local.
- SAE_local requires more features in total over the dataset to explain the same amount of network performance compared with SAE_e2e and SAE_e2e+ds.
Moreover, our automated interpretability and qualitative analyses reveal that SAE_e2e+ds features are at least as interpretable as SAE_local features, demonstrating that the improvements in efficiency do not come at the cost of interpretability. These gains nevertheless come at the cost of longer wall-clock time to train (see article for further details).
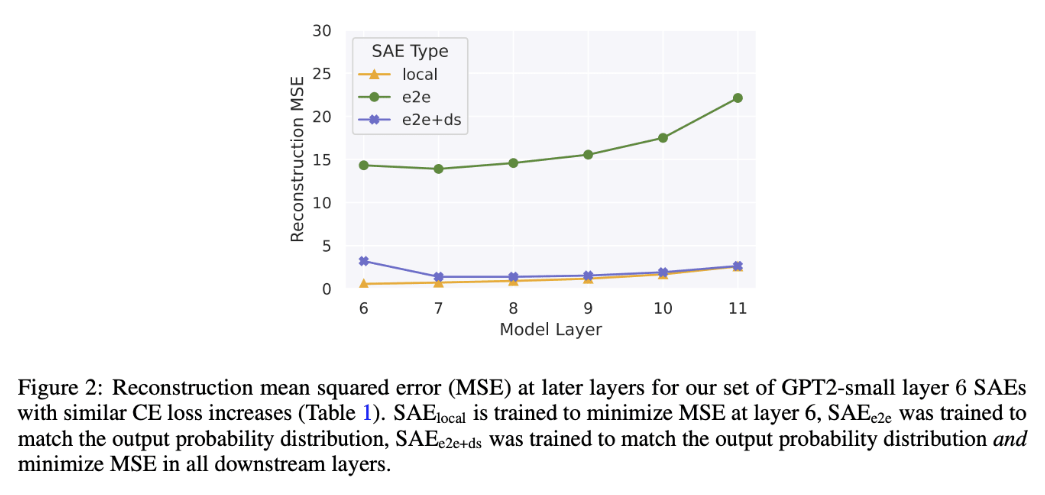
When comparing the reconstruction errors at each downstream layer after the SAE is inserted (Figure 2 below), we find that, even though SAE_e2es explain more performance per feature than SAE_locals, they have much worse reconstruction error of the original activations at each subsequent layer. This indicates that the activations following the insertion of SAE_e2e take a different path through the network than in the original model, and therefore potentially permit the model to achieve its performance using different computations from the original model. This possibility motivated the training of SAE_e2e+ds, which we see has extremely similar reconstruction errors compared to SAE_local. SAE_e2e+ds therefore has the desirable properties of both learning features that explain approximately as much network performance as SAE_e2e (Figure 1) while having reconstruction errors that are much closer to SAE_local.
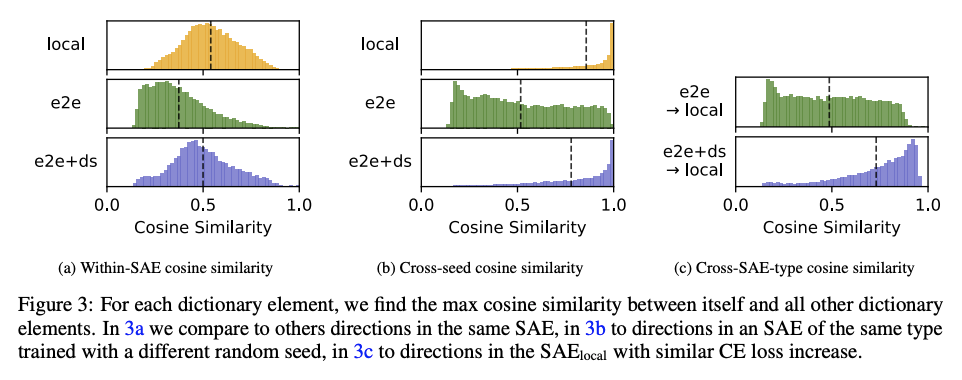
We measure the cosine similarities between each SAE dictionary feature and next-closest feature in the same dictionary. While this does not account for potential semantic differences between directions with high cosine similarities, it serves as a useful proxy for feature splitting, since split features tend to be highly similar directions. We find that SAE_local has features that are more tightly clustered, suggesting higher feature splitting (Figure 3a below).
We also find that SAE_e2e does not robustly find the same directions with a different random seed, while SAE_local and SAE_e2e+ds both do (Figure 3b). Further, SAE_e2e+ds finds much more similar directions to SAE_local, while SAE_e2e directions are dissimilar (Figure 3c).
In the paper, we also explore auto-interpretability of features, and qualitative differences between SAE_local and SAE_e2e+ds.
Acknowledgements
Johnny Lin and Joseph Bloom for supporting our SAEs on neuronpedia and Johnny Lin for providing tooling for automated interpretability, which made the qualitative analysis much easier. Lucius Bushnaq, Stefan Heimersheim and Jake Mendel for helpful discussions throughout. Jake Mendel for many of the ideas related to the geometric analysis. Tom McGrath, Bilal Chughtai, Stefan Heimersheim, Lucius Bushnaq, and Marius Hobbhahn for comments on earlier drafts. Center for AI Safety for providing much of the compute used in the experiments.
Extras
- Library for training e2e (and vanilla) SAEs and reproducing our analysis (https://github.com/ApolloResearch/e2e_sae). All SAEs in the article can be loaded using this library, and we also provide raw SAE weights for many of our runs on huggingface.
- Weights and Biases report that links to training metrics for all runs.
- Neuronpedia page (h/t @Johnny Lin @Joseph Bloom) for interactively exploring many of the SAEs presented in the article.
Read the full paper here.