The Evals Gap
In our engagements with governments, AI safety institutes, and frontier AI developers, we found the concept of the “evaluation gap” (short: ‘evals gap’) helpful to communicate the current state of the art and what is needed for the field to move towards more robust evaluations. In this post, we briefly explain the concept and its implications. For the purpose of this post, “evals” specifically refer to safety evaluations of frontier models.
Evals have become a prominent tool underpinning governance frameworks and AI safety mechanisms. Given that, we are concerned that policymakers and industry players both (i) overestimate the number of currently available high-quality evals and (ii) underestimate the time it takes to develop them. In our experience, available evals are not sufficient (in quality and quantity) to robustly identify the capabilities of existing and near-future models.
We call this overarching idea the evals gap. Unless more focused attention is paid to this gap and efforts diverted to closing it, we expect this trend to continue and, subsequently, the gap to increase.
We think it is possible to close the evals gap. This post serves as a call to action to be more ambitious with evals efforts, e.g. dedicate more resources to the science, development, and running of evals.
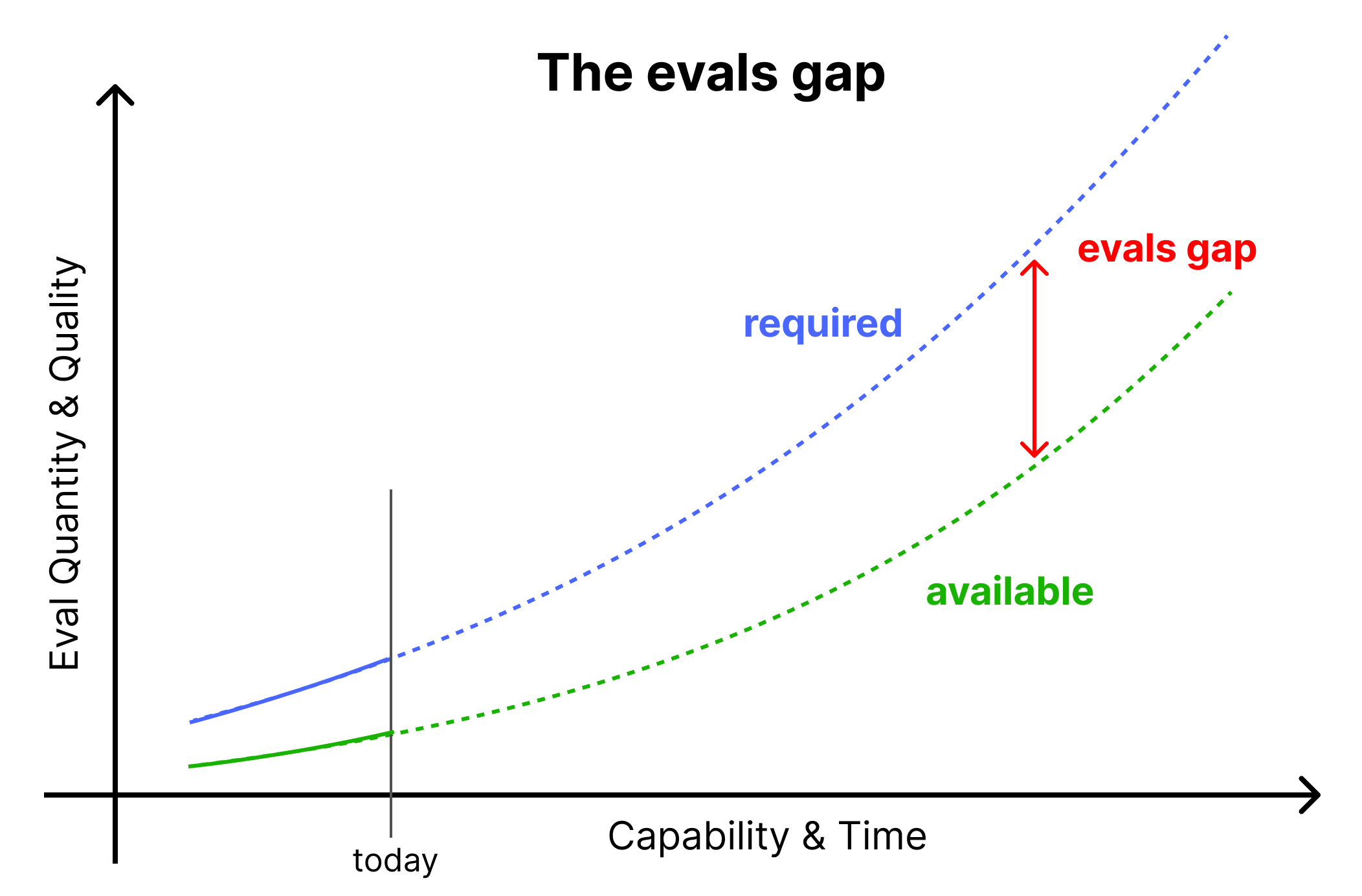
The quality and quantity of evals required to make rigorous safety statements could outpace available evals. We call this concept “the evals gap.”
Evaluations underpin many high-stakes decisions
Many high-stakes decisions in company-led and government-led frameworks are reliant on the results of evals. In voluntary commitments such as Anthropic’s Responsible Scaling Policy, OpenAI’s Preparedness Framework, and Google DeepMind’s Frontier Safety Framework, mitigation measures and deployment decisions are directly tied to the identification of specific capabilities through evals. While these voluntary policies differ between companies, some consensus on best practices, including the role of evals, is beginning to be reached through e.g. the Frontier AI Safety Commitments. Evals are also a core part of legislation and governance frameworks, such as the EU AI Act or the US Executive Order.
We think evals are an important tool for AI governance and AI safety, and we think it is good that governments and AI companies use them in their safety frameworks. However, given the high stakes involved, it is crucial to ensure that the evals used to underpin these decisions are adequate.
Current evaluations are insufficient to underpin high-stakes decisions
Many important evals don’t yet exist
The aforementioned safety frameworks sometimes require evals that either do not yet exist or, where they do, evals that are in an early development phase and incapable of of generating sufficiently robust evidence.
For example, the EU AI Act (Article 51) states, “A general-purpose AI model shall be classified as a general-purpose AI model with systemic risk if it meets any of the following conditions: (a) it has high impact capabilities evaluated on the basis of appropriate technical tools and methodologies, including indicators and benchmarks;[…]” In this case, the “high impact capabilities” in question are yet to be specified. Until that happens, evaluators are required to guess which evals will be required to identify them.
In their Responsible Scaling Framework(October 2024 version), Anthropic writes, “We are currently working on defining any further ‘Capability Thresholds’ that would mandate ASL-4 Required Safeguards […]”. This statement indicates that a full ASL-4 evals suite that could provide strong evidence about catastrophic risks does not yet exist (Though, some of the respective capability evaluations already exist, e.g. Benton et al., 2024)1.
Coverage is typically low
From our interactions with others in the evals ecosystem (e.g. AI developers, third-party evaluators, academics, AISIs, and other government agencies), we noted a consensus that the coverage of evals is low, i.e. that there are much fewer evals than needed for any given risk domain2. Thus, even when there exist evals for a given risk domain, they only cover a small number of potential threat scenarios. A shared belief among the people we spoke to was that existing evals can only spot-check their specific risk domain and should not be conflated with a rigorous assessment.
In general, we want evals to be predictive of real scenarios, i.e. their results to indicate what we should expect from real deployment situations. This is a big assumption since real deployments can capture countless different use cases across a wide variety of scenarios and users. Therefore, creating good coverage is a significant endeavor that would optimally result in a comprehensive suite of evals per risk domain.
While there are many important efforts to create new and better evals (e.g. Kinniment et al., 2023; Phuong et al., 2024; Mouton et al., 2024; OpenAI, 2024; Benton et al., 2024, see more here), the field is nowhere near having good coverage of all relevant risks and domains. Thus, the existing evals mostly function as a spot check for their corresponding risk domains, providing some evidence but not sufficient coverage.
Development and interpretation of evals is complicated
The development of a single suite of high-quality evals can require the full-time effort of a small research team for multiple months. This process can come with many unforeseen challenges.
For example, most safety frameworks (e.g. Anthropic’s RSP, Google DeepMind’s FSF, OpenAI’s PF) mention risks from model autonomy and sometimes even specifically talk about a model’s ability to accelerate AI R&D. SWE Bench (Jimenez et al., 2023) is an evaluation framework consisting of 2,294 software engineering problems drawn from real GitHub issues. It is often used to compare the software engineering abilities of LM agents and used as a proxy for autonomy and AI R&D capabilities. However, it was later found that a significant number of these coding problems were underspecified or otherwise unsolvable. Thus, any reported results on the original version of SWE Bench were misleading. This led to the introduction of SWE-Bench Verified, which only includes coding problems confirmed to be solvable and required hiring many skilled software engineers to manually validate each sample.
This example should not be misconstrued as a criticism of the original SWE-Bench authors. Rather, it is a demonstration of the fact that building large-scale, high-quality evaluation benchmarks is complicated and expensive. Furthermore, there are various issues with other equally widely used benchmarks like MMLU or BBQ, third-party evaluation frameworks, model-written evals, and more (see Anthropic’s Challenges in evaluating AI systems for details).
On top of that, interpreting evals results too can be challenging.For example, despite noteworthy outcomes on our most recent publicly available evals suite (see o1-preview system card), we found it challenging to formulate clear and robust takeaways or tie them to very concrete recommendations for the developers. The three main reasons for this are (a) defining clear capability thresholds and designing evals for them is still a nascent research area (and, in our opinion, part of the evals gap); (b) even if we have clear thresholds, the empirical evidence might be insufficient or hard to interpret; (c) with current techniques, there is a concern that the model’s capabilities were not maximally elicited.
Proper elicitation is an unsolved research question
In evals, we often encounter the problem that “absence of evidence is not (strict) evidence of absence.”3 Just because a model didn’t show a capability in our eval does not mean it doesn’t have this capability under different circumstances.
So far, we neither have a principled way to quantify “how hard we tried” nor a way to upper-bound the model’s capabilities through evaluations. This poses a challenge because we cannot accurately estimate what capabilities the model will have after widespread deployment (and thus which harm it might create).
As an analogous example, consider jailbreaking. AI developers typically extensively evaluate their model for jailbreaks before release, i.e. they check if they can find clever ways to get their model to respond to harmful queries. Presumably, their internal efforts conclude that the model is hard to jailbreak before they release it. Nevertheless, in almost all recent releases, a model has been jailbroken by users within a few hours or days available. This is comparable to the problem we face with evals. A small number of evaluators have a limited amount of time to assess the model’s capabilities and then make a prediction about the revealed capabilities during deployment. We currently don’t have a rigorous theory of predicting these revealed capabilities.
Without action, the evals gap may widen
Higher capabilities require more evals. Increased capabilities imply that the model is able to do a larger number of tasks. For example, GPT-4 can be used in many more use cases than GPT-2. Therefore, the space that evals for GPT-4 have to cover is much larger than for GPT-2.
Higher capabilities require more complex evals. The more complex the capabilities of models, the more complex and time-consuming it is to foresee, develop, and run evals. For example, consider that until recently, we could evaluate most relevant LLM behaviors with QA benchmarks. Since models are now capable enough of acting as LM agents, evals have to be increasingly complex tasks, which significantly increases the overhead per eval.
Increased stakes for evals in the future. Right now, it appears that most models are not capable enough to trigger evals with high-stakes consequences. For example, OpenAI assessed their o1-preview model to be medium capable of CBRN and persuasion4. Since only models with a post-mitigation score of “medium” or below can be deployed, o1-preview could be deployed. Anthropic has assessed their Claude-3 model family to be in category ASL-25, where most costly mitigations only start with ASL-3.
As capabilities in AI models increase, more and more evals identifying specific thresholds tied to high-stakes reactions will get surpassed and trigger increasingly important consequences. Eventually, the results of evals will have a direct effect on billion-dollar deployment decisions. For example, Anthropic’s ASL-3 specifies a large number of mitigations and actions on model security (corresponding to SL-4 in RAND’s Securing AI Model Weights report). These mitigations could take significant time to implement, which would lengthen the time to deploy their model and may come at a direct financial cost. If a model provider has to postpone their deployment by multiple months due to a relevant threshold being passed and having to improve their safety guardrails, they might lose out on important investments.
We expect that these increased stakes will lead to increased pressure on and scrutiny of evals and their results. Furthermore, in uncertain cases, AI developers might be incentivized to criticize these evals, question their legitimacy, or, in extreme cases, even go to court with legislators to reduce their financial burden. This necessitates that the quantity and quality of evaluations rise to the challenge posed by rapid AI progress. Only then can evals provide a meaningful mechanism to rigorously test for all relevant risk domains and support other safety mechanisms in a defense-in-depth approach.
Closing the evals gap is possible
With sufficient foresight, we can close the evals gap. All of the aforementioned problems are solvable with more resources, people, and time. However, AI progress is fast, and high-stakes decisions will have to be made in the near future. Given the magnitude of the stakes, these decisions will likely be made with whatever evals are available at the time and will not be put on hold until better evals are developed. Therefore, we think closing the evals gap is an urgent priority.
We suggest the following efforts as initial areas for improvement:
- Directly fund evals development: Merely funding the running of evals is not sufficient. Conducting evals is often only a small fraction (e.g. 10%) of the total effort and cost going into evaluations. We recommend to:
- Fund an external ecosystem of evaluation builders. We recommend casting a wide net, e.g. including private organizations, non-profits, academic labs, and individual researchers.
- Fund government bodies such as AISIs or AI offices well so that they can hire the technical talent needed to develop, run, and judge evaluations.
- Grow the evaluation teams within frontier AI companies such that they can better prepare for systems with increased capabilities.
- Fund the science of evals: Improvements in the science of evals benefit the entire field. For example, a better understanding of how to design high-quality evals at scale would both increase their usefulness and reduce their costs.
- Shape market incentives: Because most evals efforts are currently based on voluntary commitments, the incentive to pay for or build evals is small. If there were stronger incentives, more people and organizations would specialize in building evals. While we commend efforts like Anthropic’s Initiative for developing third-party model evaluations, market incentives would have to change more broadly for an ecosystem to develop at the required pace.
- This is not a specific criticism of Anthropic. We think it is good that they state their level of preparedness and their plans in public to expose them to external feedback. ↩︎
- Note that these reflect our interpretations of these conversations and are not the result of more systematic efforts such as structured interviews. ↩︎
- Technically, absence of evidence is some evidence of absence. The core point is that it should not be used as conclusive evidence unless we have exhaustively tested all options or have other arguments that imply strong evidence of absence. ↩︎
- This has not been externally verified. ↩︎
- This has not been externally verified. ↩︎